- Excellence of a dev organization is defined as “the ability to execute given objectives quickly and accurately.”
- To achieve this, dev organizations must continuously re-evaluate their performance at three key points:
- Identify bottlenecks in the process from dev to deployment, and continuously explore how to excel at resolving them.
- The deployment of one product must be completely independent from other unrelated products.
- Comprehensive monitoring must be established across all deployed products.
The era where software engineering is everything has begun. Through software engineering, humanity has achieved efficiency gains of multiple of thousands to millions over previous generation, and problems that were once unsolvable can now be addressed through software engineering.
However, we still experience the complete opposite experience either as consumers, or doubt our own outcomes as producers - “Is this truly the best we can do?” or “Aren’t the products still far behind compared to the pace of technological advancement?”, etc. While American big tech companies seamlessly serve personalized contents to billions of users with global-scale traffic, many Korean banks still conduct regular 30min maintenance at midnight, demonstrate amateurism against traffic increases and outages, while still taking conservative approaches to adding new features.
This fundamentally stems from society-or management-level misconception about properly defining the “core objectives” and standards of “organizational excellence”, which are needed to meet evolving user demands when operating dev organizations. Organizations that have decided to solve problems through software engineering need to redefine these “standards of excellence” to accomplish the objective more efficiently. The importance of this thesis is independent upon the size of organization-even the smallest and most agile startup won’t be able to build competitive advantage in software engineering markets if they have the wrong standards.
Objective: Defining Excellence in Dev Organizations
Excellence in a dev organization is dead simple yet straightforward: “An organization that can execute given objectives quickly and accurately” is an excellent dev organization. All other elements are merely means for achieving this objective.
Why is speed important? Because it’s the essence of competitive advantage that software engineering can build. Software products must be: 1. Fast - the time from consumer requirements to usable product must be short, and 2. Agile - able to respond nimbly when requirements change. Software products must build advantage over competitors by rapidly responding to user requirements through this speed differentiation.
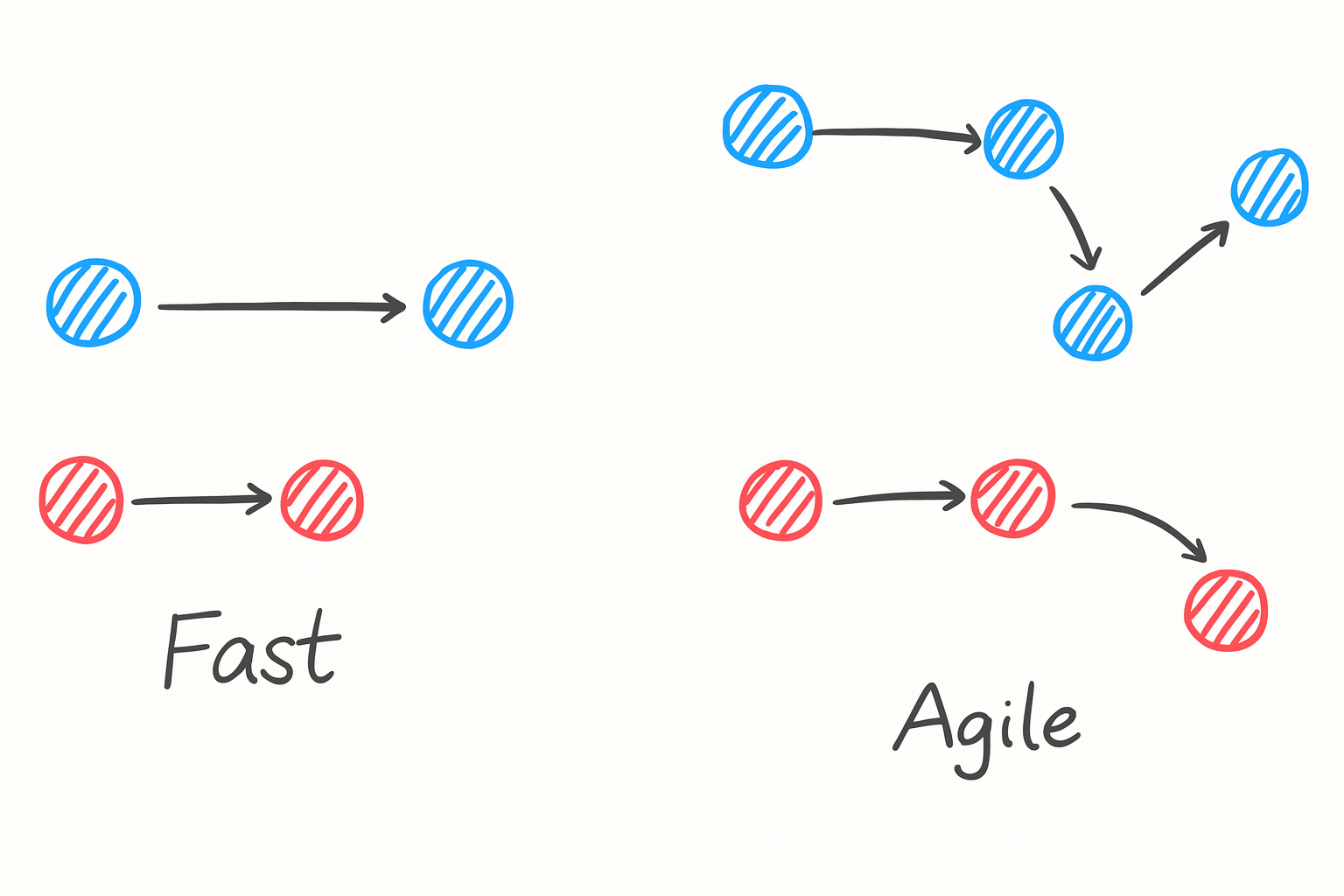
Why is accuracy important? Because the pursuit of speed inevitably leads to accuracy deficits. Founders or developers who write a Minimum Viable Product (MVP) would expect the entire world to use their product immediately upon deployment, while in reality they must begin an infinite iteration loop of identifying various requirements for each user and improving the product accordingly. The product must evolve to fit the situations of customers and objects in each circumstance, just like a logic circuit. The more sophisticated the product’s precision becomes, the more competitive your product is upon the market.
Once the objective for excellence is well-defined, the organization will have to establish specific key results and action items to achieve it. These can vary greatly depending on the nature of the problems the organization is solving, or its revenue model. This article will introduce three most common core values that B2C agile organizations should pursue. Before beginning the next section, it’s worth emphasizing that objectives must always take precedence over means. If executing a means fails to achieve the objective, the decision must be boldly withdrawn and the failure must be retrospectively analyzed-organizations that aren’t able to withdraw their wrong decisions can never achieve excellence.
Key Results: Outcomes and Action Items for Achieving Excellence
1. Continuously identify where bottlenecks exist from planning to deployment
Once product requirements are defined and implementation specifications are finalized, the deadline to deployment is determined by the engineering organization’s excellence. All software products-from simply changing the text on a button to creating a completely novel securities app—are subject to the same rule. Part or all of the development organization must maintain consistently high performance despite constantly changing requirements, and the biggest obstacle making this process difficult can be abstracted as a “bottleneck”.
Developers are commonly regarded as truly terrible at estimation. Among not just software companies but general engineering work (construction, smelting, refining, shipbuilding, …), software engineers would likely be the profession that most fails to meet estimations. This cannot overlook the fact that software engineering faces overwhelmingly more frequent specification and methodology changes compared to other engineering disciplines. Once the maximum occupancy of a 30-story building is determined the number won’t easily change for decades, but it’s not uncommon for a site visited by thousands of people today to receive millions of visitors the next day.
Therefore, whenever developers encounter a bottleneck that demolishes their estimation, they must continuously consider: 1. Why this point became a bottleneck, and 2. What efforts should be made to avoid repeating it. Some days the database processing capacity might be the bottleneck, other days the gradual deployment process to multiple nodes in the infrastructure might be the bottleneck, build time might be the bottleneck, or even a colleague who is slow with code reviews might be the bottleneck. By persistently working to recognize and address bottlenecks so they’re not encountered again, developers’ estimations gradually become more accurate and approach to excellence.
Common Action Items
- After product deployment is complete, take sufficient time to retrospect on how things differed from estimation and consider how not to repeat these issues.
- At the end or start of each day, retrospect on “which tasks took the most time yesterday/today.”
- Not just you, but excellent engineers worldwide are intensely working to solve the same bottlenecks. Consider how to effectively borrow their ideas.
- Example: Certain build tools can reduce build time to 1/10 while maintaining the existing structure.
- Example: To reduce the probability of encountering unexpected problems during development or after deployment, utilize strong type systems and write effective tests at core logics.
- Example: Use a monorepo or library structure that easily shares solutions to common problems so that colleague developers don’t repeatedly encounter problems you’ve already faced.
2. The deployment of one feature must be completely independent from other features
As the number of small-unit products or features within an organization’s product increases, problem complexity increases not proportionally but in at least a squared rate. The core reason for this steep increase in complexity is that changes to specific features affect the operation of other features. This impact can manifest in various phenomena-one day, development of Feature A might break the code build of Feature B, or another day, deployment of Feature A might cause increased traffic that leads to service failures in Feature B.
Through decades of operating dev organizations, humanity has realized that the key idea of solving this issue is “independence between features”. Anyone who has studied basic computer science will understand how dramatic it improves the overall throughput when the complexity of solution is improved from a rate of to for problem size . Transitioning from a dependent service mesh to an independent service mesh produces an effect similar to reducing complexity to .
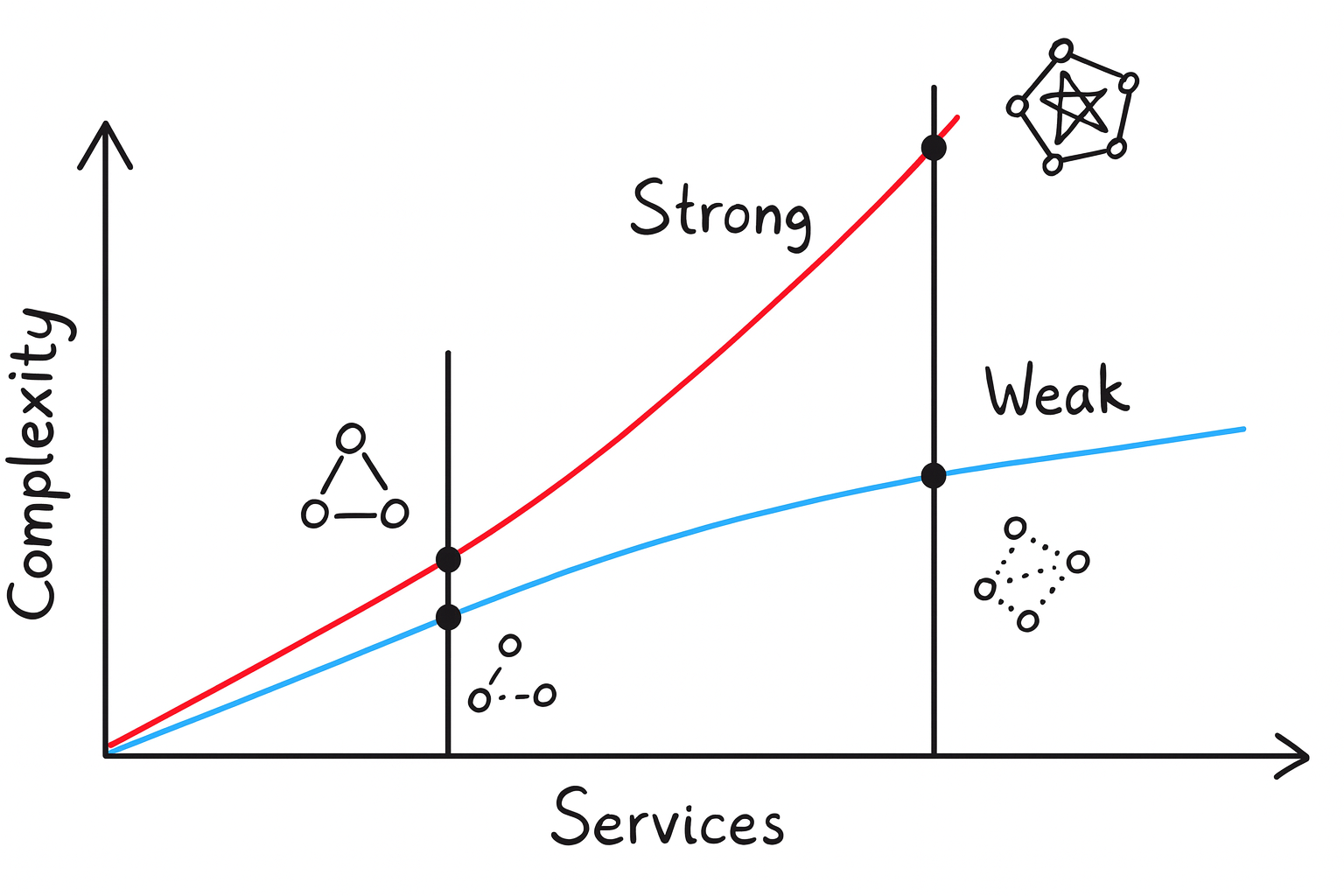
Another effect of service independence worth noting is the “reduction of deployment fear.” In a dependent service mesh structure, developers fear deployment because they cannot accurately assess the impact their deployment will have on other services and ultimately the entire product. In contrast, in an independent service mesh, the problems one’s deployment can cause won’t grow beyond failures in the service oneself is responsible for.
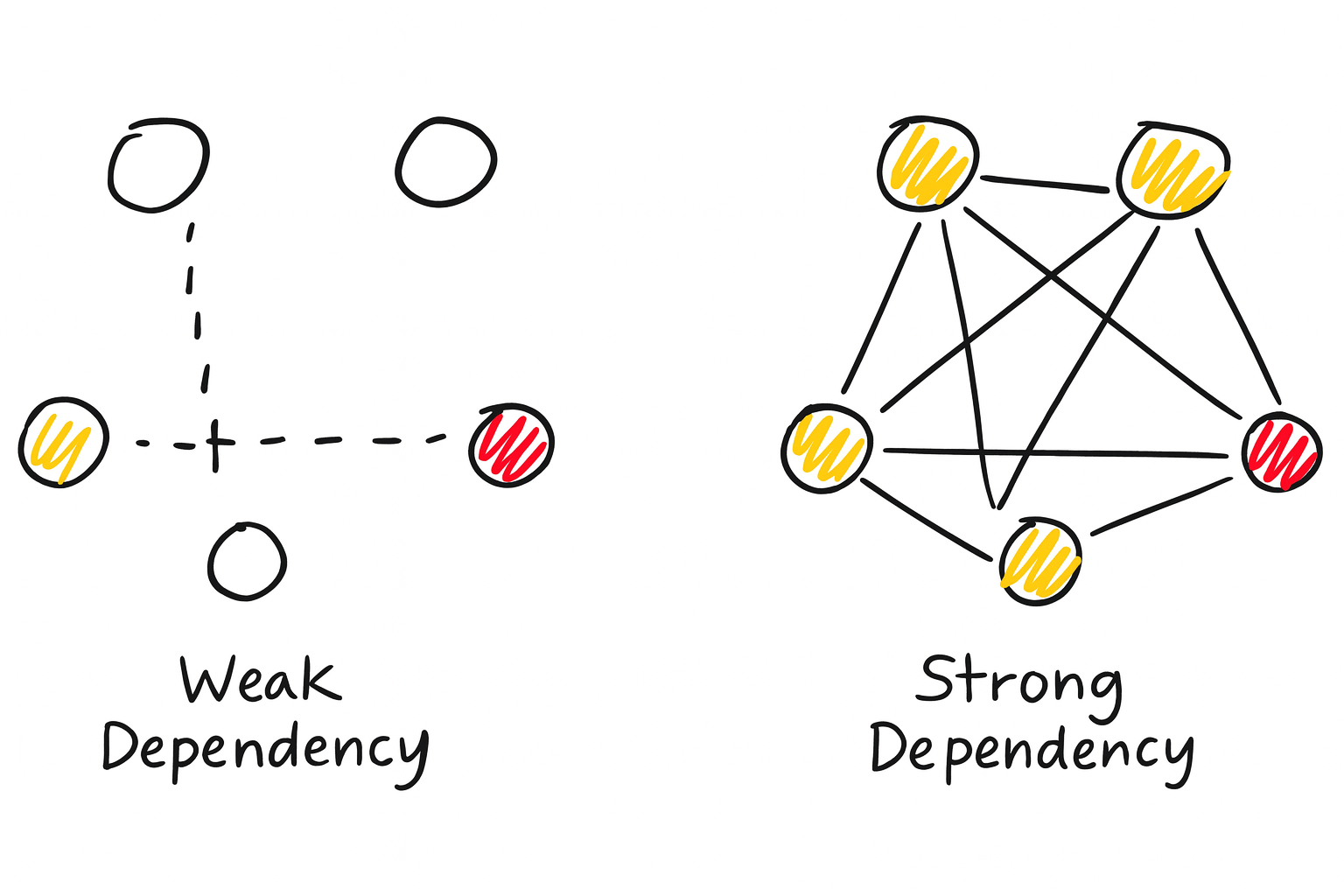
Many companies pour tremendous resources into achieving this independence, and some companies invest even more resources here than in the product dev organization. As it is such an important and well-researched area, there are countless proposed methodologies and solutions to achieve independence. Excellent developers must clearly distinguish between objectives and means, introduce appropriate solutions for the size of problems the organization is currently facing, and apply the introduced solutions well.
Common Action Items
- Feature separation by responsibility - Once features are well-defined, define the responsibilities each feature should carry and write technical specifications accordingly. If there’s logically no responsibility to share between features, dependencies should not exist at the specification level.
- MSA - Replace service dependencies with API communication and completely eliminate code-level dependencies.
- Caveat: MSA is not a silver bullet. Even with monolithic architecture, each service can be independent, while the achievement for objective may still fail in MSA structure if each microservice is designed to be strongly dependent.
3. The entire process before and after product deployment must be monitored
Unlike the two goals above, monitoring is a process that occurs after deployment, yet it significantly impacts speed and accuracy-the main objectives of excellence. Not only in software engineering but in various crisis response theories (firefighting, law enforcement, …), it’s noted that “failures cause exponentially higher damage the later they’re discovered in the overall pipeline.” From an agile product development perspective, the process a product goes through from completed planning to deployment can be broadly abstracted as tech spec definition - implementation - testing - QA - deployment. According to the above theory, a problem of tech spec definition is addressed cheapest when caught during implementation, and if caught at deployment, it will incur far greater organizational costs compared to the former case.

The main objectives that monitoring must achieve to pursue excellence can be divided into two categories. First one is splitting the final stage of deployment into multiple sections to enable problem detection in the early stages of deployment. If an organization using progressive deployment has built an excellent monitoring system, they can detect problems and prevent failure propagation even when approximately 1% of users encounter a deployment version causing failures. Organizations without proper monitoring would detect and respond to failures long after all users have encountered the new deployment version, which, despite being the same deployment stage, causes the organization to pay far greater costs.
The second is creating good metrics to measure organizational excellence through excellent monitoring, and establishing action items to improve excellence based on these metrics. Once you begin discovering large and small failure points through monitoring and experience resolving these issues before they escalate into major costly problems, the dev organization will and must continue to contemplate and repeat methods to mitigate discovered problems, reduce their scope of impact, and minimize developer intervention while maintaining the same responsiveness. Problems discovered through monitoring trivially increase proportional to where organization or problem size grows -fold. Nonetheless, the time spent responding to increasing number of issues must be kept far under -fold, and organizations that fail to achieve this will never be able to achieve both scaling and excellence simultaneously.
Common Action Items
- Strengthening individual developer accountability
- Alerts - Appropriate alerts and alert level settings for all problems that can be detected programmatically, alert escalation protocols matching organizational structure
- Building long-term storage pipelines for various technical metrics
- Identifying and retrospecting failure frequency and main problem points based on stored data
- Dev organization culture where active technical discussions occur to mitigate these issues
Conclusion
I’ve summarized the core objectives that organizations pursuing excellent dev organizations should set, three performance indicators to achieve these, and commonly executable action items. It is worth emphasizing again at the article’s end that it’s very important that objectives are accurately set before deciding on means, so the readers will have to take the presented action items as mere examples, and it’s much more important to set appropriate action items matching your organization’s structure and requirements.
In closing, I hope readers to trust that the pursuit of an excellent development organization gives developers themselves greater satisfaction than they might think. Breaking down self-set goals into action items and achieving them is an enjoyable process for every individuals. When one is a member of an organization whose core value is speed, the experience of increasing that speed through your contributions not only provides tremendous personal satisfaction but also has practical yet huge impact on the organization. When the endless pursuit for excellence and the pattern of fulfilling your role as a developer while elevating the entire organization’s productivity becomes internalized, growth as a developer who can build up excellent organizations-who are extremely rare in the job market-will begin, and I’m confident that this process can bring you great joy.
Acknowledgments
Thank you to all who graciously read and reviewed this article.
Original article translated by Claude Sonnet 4.5, reviewed by author. All figures created by author, refined by GPT 5.